I’m excited to announce a first take at enabling lyrics to be viewed in any of the South Indian languages (+ devanagari)!
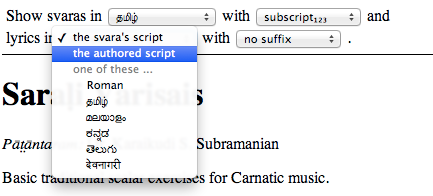
In the previous post, I talked about choosing the script in which to show the svaras of the notation. I’d mentioned that transliteration support for lyrics is in the works. Well, you can now take a look and let us know what you think.
Note that we’re trying here to provide transliteration into a target language no matter what script the lyrics were entered in the authored document. Indeed, I eventually intend to support mixed scripts (which already works to some extent).
I believe this is a big step in increasing the accessibility of compositions in Carnatic music to the whole of South India that engages in it and are happy to make this contribution to the music culture.
I’ve used the ISO 15919 standard for Roman transliteration of Indic scripts as the canonical representation. Most of the diacritics relevant to South Indian languages and to Devanagari are supported, though not all are available as of this writing in the editor helper interface.
While the current implementation is useful in its current state, a number of issues remain to be addressed -
-
Tamil script folds multiple devanagari consonants into single letters and the actual pronunciation is inferred from context. This makes it non-trivial to transliterate from tamil to other scripts. Nothing short of a corpus can help solve this problem. One step I’ve taken is to support disambiguating numerical subscripts (like க₁, க₂, க₃, க₄) when transliterating from Tamil to other scripts.
-
The use of ந versus ன (tamil) is dependent on word position of the letter though there is no practical difference in pronunciation. Given lyrics are already split into syllables in the notation, this becomes hard. Though the ISO 15919 standard provides separate diacritics for these two, I’d like to do some context-based determination to ease lyrics typing.
-
In general, accurate transliteration will require incorporating phonetic rules to disambiguate cases in each language separately. This will take time, but we’ll eventually solve it. Fortunately, the canonical roman diacritics representation is unambiguous and any fixes added will solve script problems across all documents.
Enjoy!
- Notations
- Tala Keeper
- Talks
Twitter · RSS